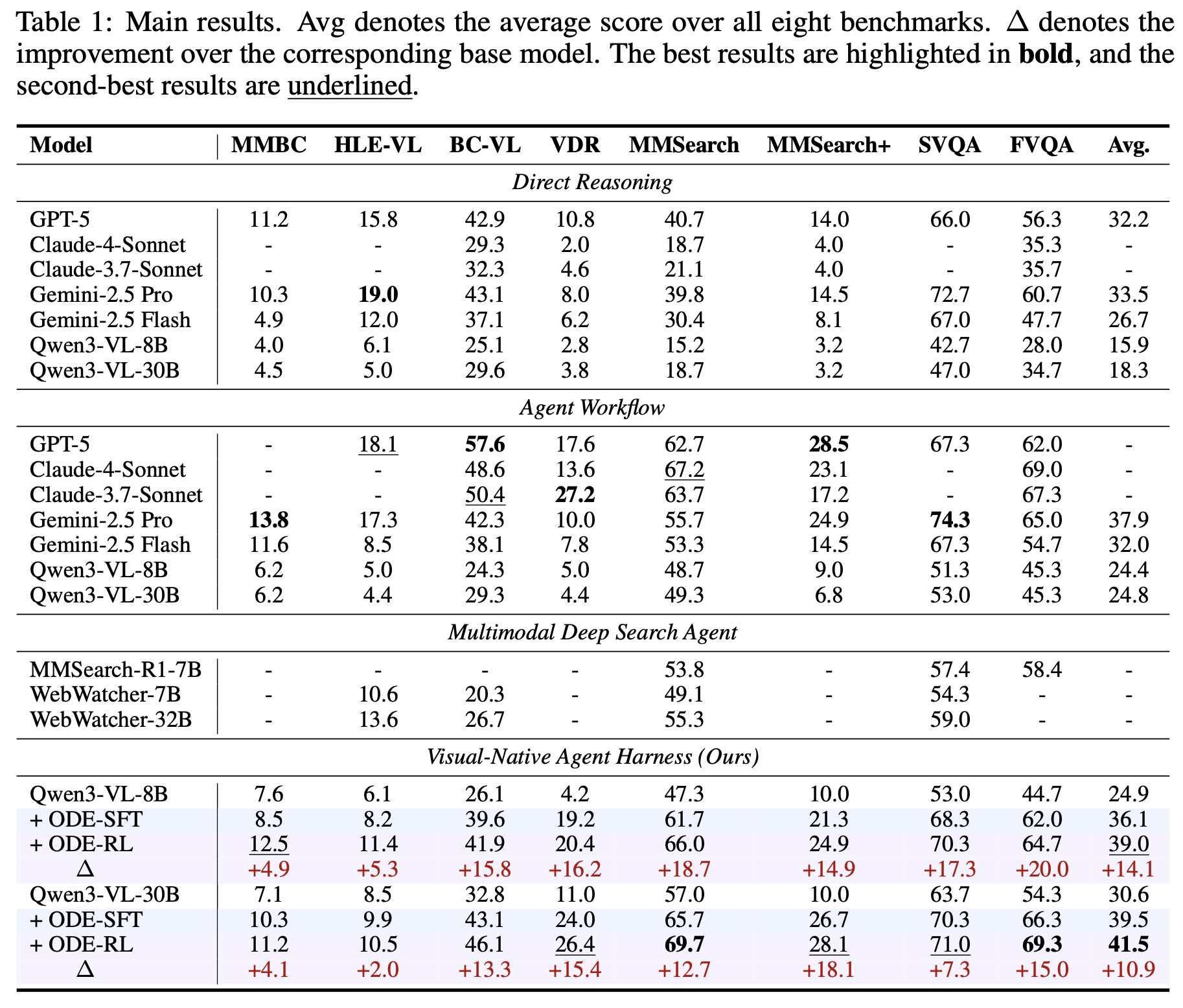
What is ODE?
ODE treats multimodal deep-search data construction as an adaptive loop over the same visual-native harness used by the target policy.
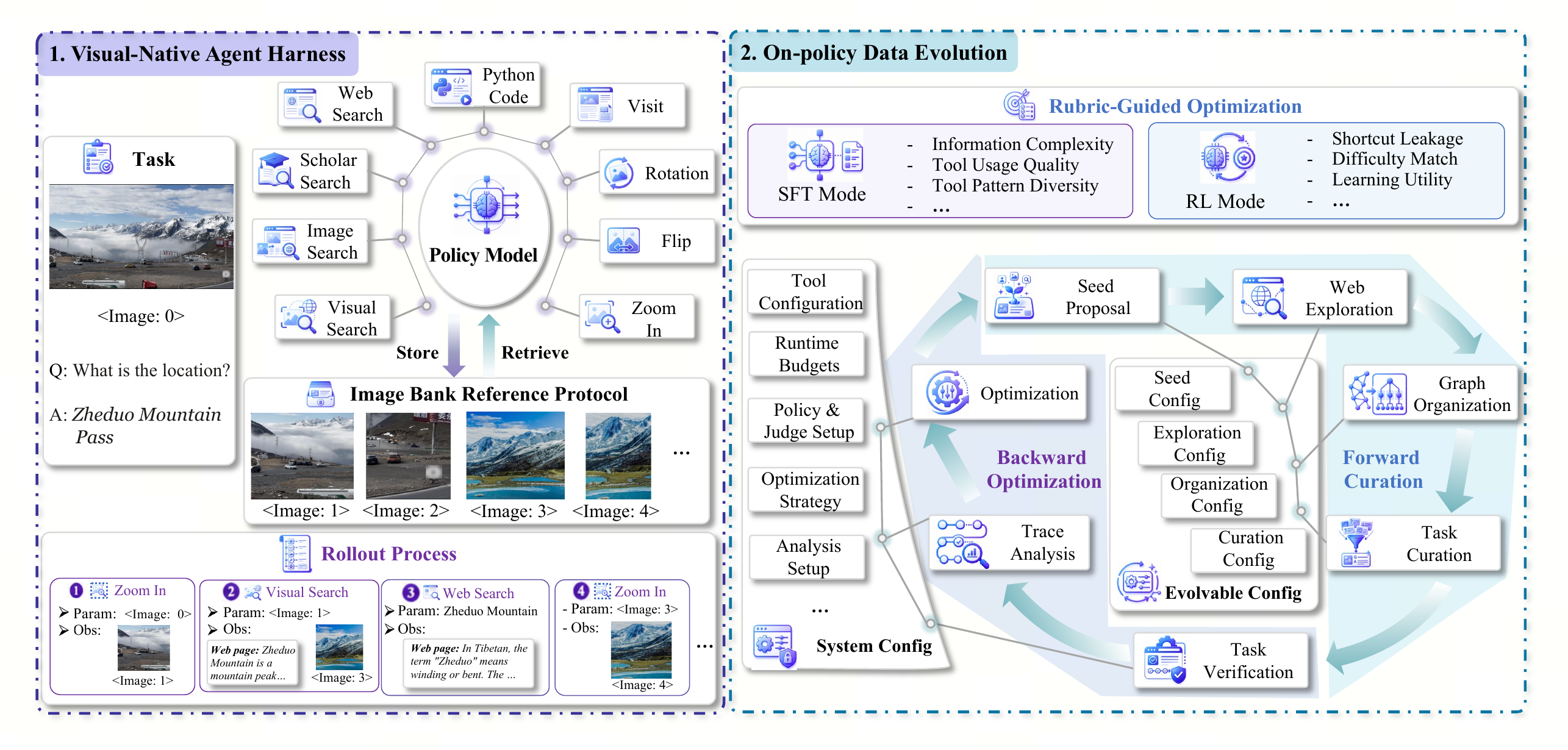
Two coupled components: a stateful visual workspace and an evolving data generator.
The left half shows the visual-native harness. The original task image and every image returned by search,
browsing, visual search, or image manipulation are registered as reusable <image:N>
handles, so later tools can crop, search, rotate, or inspect evidence produced by earlier steps. The right
half shows ODE: a forward pipeline proposes seeds, explores web evidence, organizes multimodal evidence
graphs, and curates verifiable tasks, while a backward pipeline rolls out the teacher or current policy,
diagnoses the traces with SFT/RL rubrics, and updates the next epoch's generation configuration.
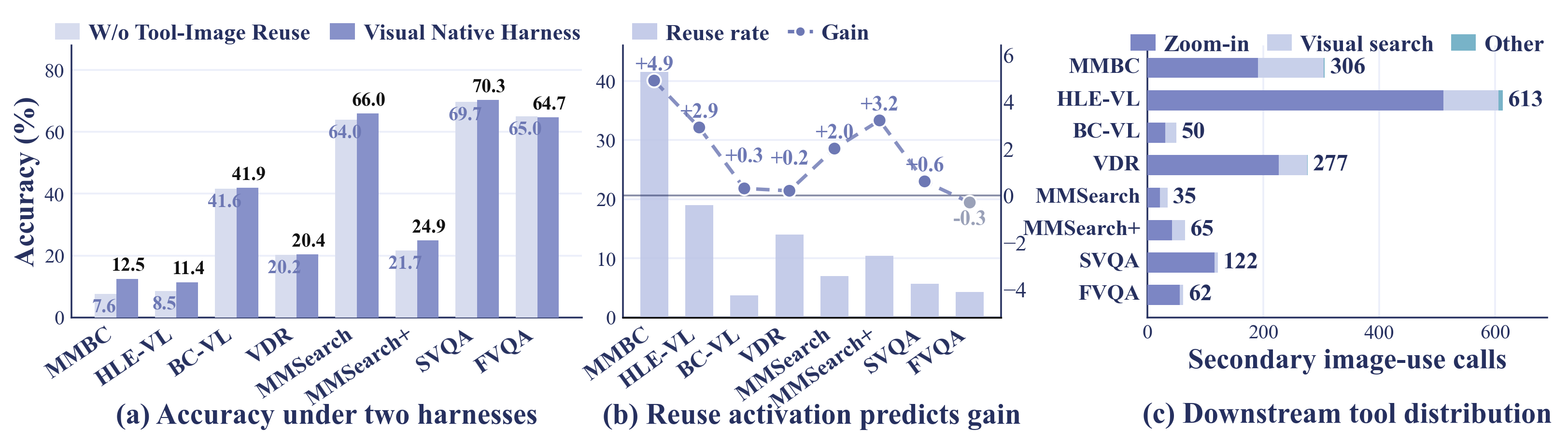
Images are no longer transient observations. They become addressable visual state that can be reused by later tool calls.
The example chains zoom-in, visual search, web search, and another zoom-in to identify and verify the location.
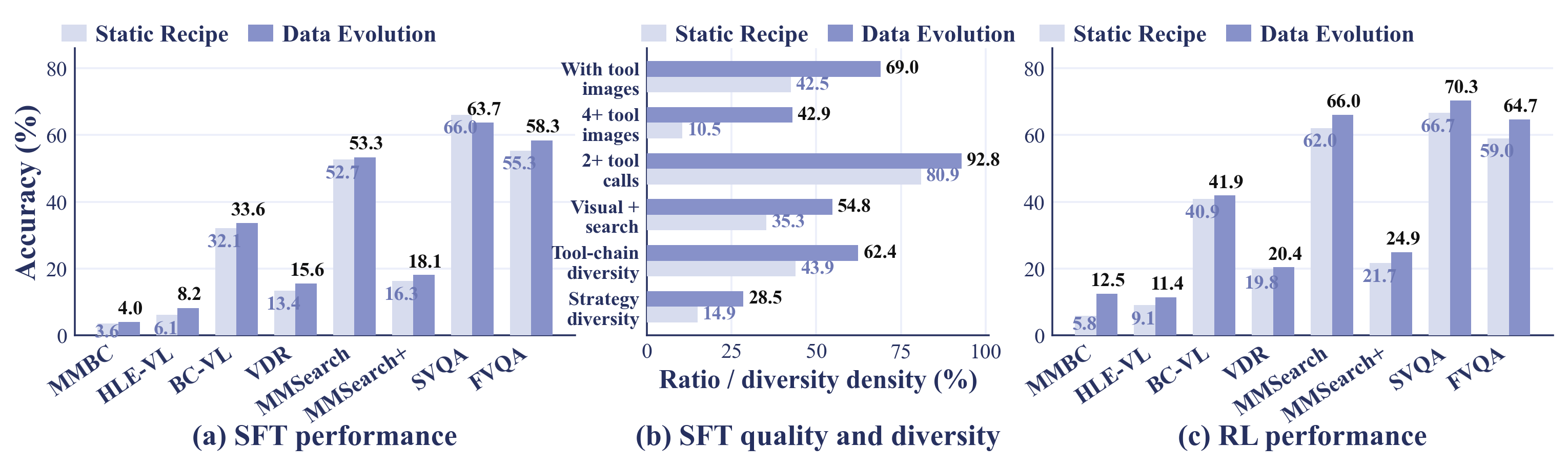
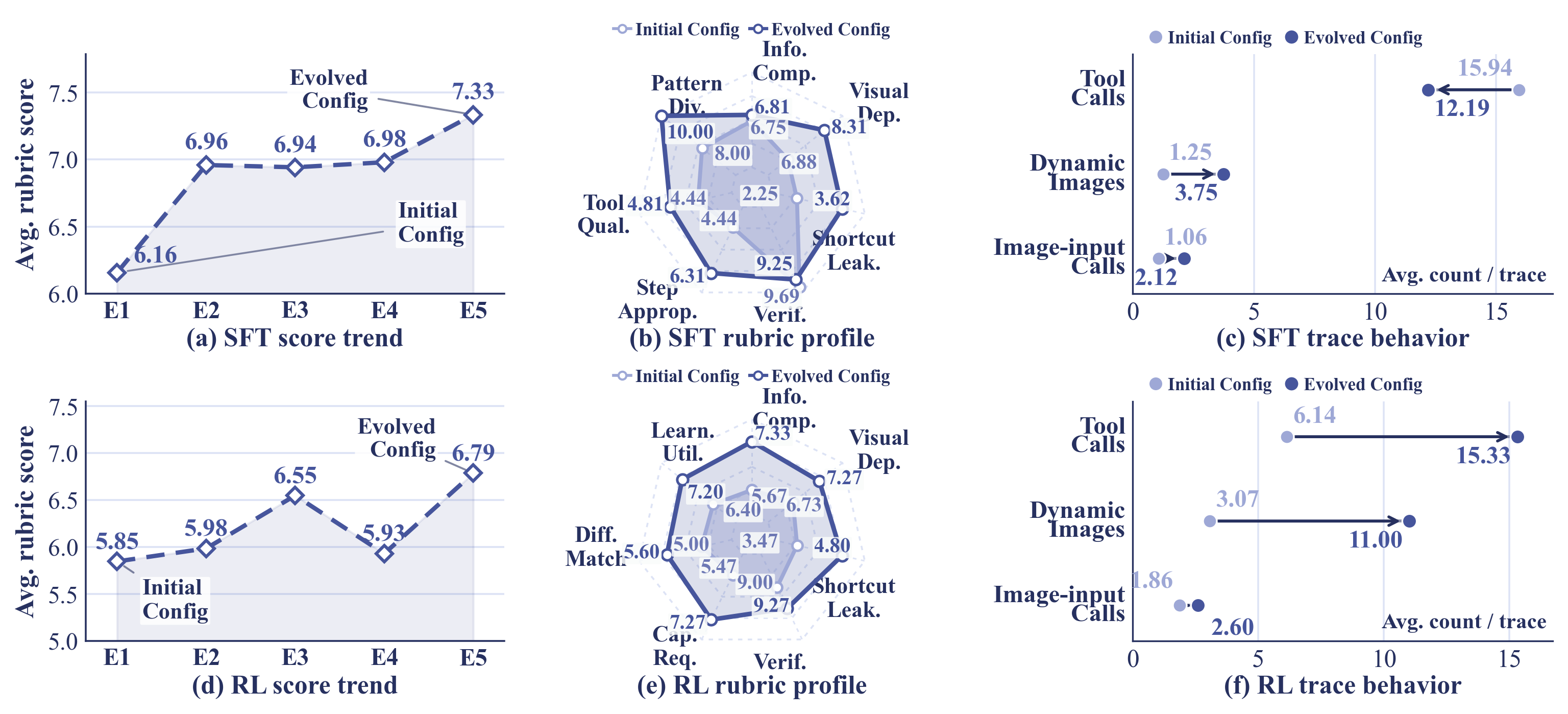
Rollout feedback edits the generator configuration instead of scaling a fixed curation recipe unchanged.